The QR algorithm is a method for finding eigenvalues. In the real symmetric case, the problem is especially clean. We are given  and we want to find numbers
and we want to find numbers  and orthonormal vectors
and orthonormal vectors  such that
such that  . Equivalently, we want an orthogonal matrix
. Equivalently, we want an orthogonal matrix  and a diagonal matrix
and a diagonal matrix  such that
such that 
Thus the eigenvalue problem is, at heart, a problem of finding the right coordinate system. The matrix  may look complicated in the standard coordinates, but if we rotate the coordinate axes so that they point in the eigenvector directions, then the same linear transformation becomes diagonal. In that special coordinate system, no longer mixes different coordinates; it merely stretches each coordinate axis by the corresponding eigenvalue.
may look complicated in the standard coordinates, but if we rotate the coordinate axes so that they point in the eigenvector directions, then the same linear transformation becomes diagonal. In that special coordinate system, no longer mixes different coordinates; it merely stretches each coordinate axis by the corresponding eigenvalue.
The QR algorithm is an iterative procedure for discovering this coordinate system. Its guiding idea is simple: repeatedly replace the current matrix by an orthogonally similar one, in such a way that the coordinate axes are gradually rotated toward the eigenvector directions. If this process succeeds, the matrices produced by the algorithm become closer and closer to diagonal matrices. The eigenvalues then appear on the diagonal.
The important point is that the iterations in the algorithm do not change the eigenvalues. They change only the orthonormal basis in which the same linear transformation is being expressed.
The algorithm
Start with  . For
. For  , perform the following two steps:
, perform the following two steps:
1. Compute the QR factorization

where  and
and  is upper triangular.
is upper triangular.
2. Reverse the factors and define

That is the unshifted QR algorithm.
At first glance, the instruction “factor  and multiply the factors in the opposite order” looks like a trick. The first important observation is that it is not a trick. Since we have
and multiply the factors in the opposite order” looks like a trick. The first important observation is that it is not a trick. Since we have  Therefore
Therefore

So each QR step is an orthogonal similarity transformation. In other words,  is the same linear transformation as , but written in a new orthonormal coordinate system. This immediately explains why the eigenvalues are preserved.
is the same linear transformation as , but written in a new orthonormal coordinate system. This immediately explains why the eigenvalues are preserved.
Moreover, symmetry is preserved. IIf is symmetric, then so is , because  Thus, starting from a real symmetric matrix, every iterate remains real symmetric and has exactly the same eigenvalues as the original matrix.
Thus, starting from a real symmetric matrix, every iterate remains real symmetric and has exactly the same eigenvalues as the original matrix.
The hope is that, as  increases, these orthogonal changes of coordinates make the matrix less and less coupled off the diagonal. That is, we want
increases, these orthogonal changes of coordinates make the matrix less and less coupled off the diagonal. That is, we want  When this happens,
When this happens,  .
.
This is the basic picture: the QR algorithm rotates the coordinate system while preserving the spectrum. The off-diagonal entries measure how far the current coordinate axes are from being eigenvector directions. As those entries decay, the diagonal entries become increasingly accurate approximations to the eigenvalues.
Proof of Convergence
Define the accumulated orthogonal matrix 
Since each QR step satisfies  unpacking gives
unpacking gives

This identity is the conceptual center of the QR algorithm. It says that is not a new linear transformation. It is the original transformation , but written in the moving orthonormal coordinate system whose axes are the columns of  . Thus the QR algorithm is trying to rotate the coordinate system until the matrix stops mixing the coordinate directions. If the columns of become eigenvectors of , then
. Thus the QR algorithm is trying to rotate the coordinate system until the matrix stops mixing the coordinate directions. If the columns of become eigenvectors of , then

QR as simultaneous power iteration: The ordinary power method begins with a vector  and repeatedly forms
and repeatedly forms  Suppose
Suppose  and
and  If
If  then
then  If
If  , the first term eventually dominates. The vector
, the first term eventually dominates. The vector  points more and more in the direction of
points more and more in the direction of  . The error is governed by the ratio
. The error is governed by the ratio 
The QR algorithm is the same idea applied to a whole basis at once. But there is a problem: if we repeatedly apply to many independent vectors, all of them tend to collapse toward the dominant eigenvector . QR prevents this collapse by orthogonalizing after every step. The first vector is pulled toward . The second vector is forced to remain orthogonal to the first, so it is pulled toward the strongest remaining direction  . The third vector is then pulled toward
. The third vector is then pulled toward  , and so on. Thus QR is the power method together with a geometric exclusion principle: once a dominant direction has been captured, the later directions must search in its orthogonal complement. This explains why QR is naturally a flag algorithm. It does not merely approximate individual eigenvectors. It approximates the nested invariant subspaces
, and so on. Thus QR is the power method together with a geometric exclusion principle: once a dominant direction has been captured, the later directions must search in its orthogonal complement. This explains why QR is naturally a flag algorithm. It does not merely approximate individual eigenvectors. It approximates the nested invariant subspaces

The convergence of the first  directions is controlled by the gap across the cut,
directions is controlled by the gap across the cut,  This is the first serious lesson of the algorithm: QR does not find all eigendirections at the same speed. Each part of the flag converges at a rate dictated by the neighboring eigenvalue ratio.
This is the first serious lesson of the algorithm: QR does not find all eigendirections at the same speed. Each part of the flag converges at a rate dictated by the neighboring eigenvalue ratio.
Theorem: Assume  where
where 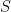 is orthogonal and
is orthogonal and  Assume the eigenvalue magnitudes are strictly separated:
Assume the eigenvalue magnitudes are strictly separated:

Finally, assume the generic nondegeneracy condition that  has an LU factorization without row exchanges. Equivalently, the relevant leading principal minors are nonzero. This condition rules out exceptional starting alignments. It is not the main idea; it is a technical condition ensuring that the standard coordinate flag is not accidentally orthogonal to the eigenvector flag.
has an LU factorization without row exchanges. Equivalently, the relevant leading principal minors are nonzero. This condition rules out exceptional starting alignments. It is not the main idea; it is a technical condition ensuring that the standard coordinate flag is not accidentally orthogonal to the eigenvector flag.
Then the QR algorithm, with the diagonal entries of chosen positive, satisfies  up to harmless sign conventions for the eigenvectors. More quantitatively, if
up to harmless sign conventions for the eigenvectors. More quantitatively, if  then there is a constant
then there is a constant 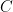 , depending on and the initial coordinate system, such that
, depending on and the initial coordinate system, such that

The theorem says exactly what the power-method picture suggests. Powers of separate eigendirections according to their eigenvalue magnitudes, and the QR algorithm records this separation while continually re-orthonormalizing the basis.
Proof: The proof becomes natural once one stops looking at the single QR step and instead looks at the powers  . The key fact is this: the accumulated matrix
. The key fact is this: the accumulated matrix  is precisely the orthogonal factor in the QR factorization of . More precisely, there exists an upper triangular matrix
is precisely the orthogonal factor in the QR factorization of . More precisely, there exists an upper triangular matrix  such that
such that

This is the bridge between QR iteration and the power method. Let us prove it. For  , the statement is just the first QR factorization,
, the statement is just the first QR factorization,  Now suppose that, for some ,
Now suppose that, for some ,  with upper triangular. Since
with upper triangular. Since  we may rewrite this as
we may rewrite this as  Therefore
Therefore

But the -th QR factorization gives  Hence
Hence  where
where  and
and  Since a product of upper triangular matrices is upper triangular,
Since a product of upper triangular matrices is upper triangular,  is upper triangular. This completes the induction.
is upper triangular. This completes the induction.
Thus the QR algorithm is not an arbitrary iteration. It is an efficient recursive way of computing the QR factorizations of  This observation explains why convergence should occur. Powers of separate eigendirections according to the sizes of the eigenvalues, and the QR factorization extracts an orthonormal basis from those increasingly separated directions.
This observation explains why convergence should occur. Powers of separate eigendirections according to the sizes of the eigenvalues, and the QR factorization extracts an orthonormal basis from those increasingly separated directions.
Now use the spectral decomposition Then  Assume that
Assume that  and assume the generic condition that has an LU factorization without row exchanges. Thus we may write
and assume the generic condition that has an LU factorization without row exchanges. Thus we may write  where
where 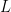 is unit lower triangular and
is unit lower triangular and  is upper triangular. Substituting this into the formula for gives
is upper triangular. Substituting this into the formula for gives  Now insert
Now insert  between and :
between and : 
Define  Then
Then  The factor
The factor  is upper triangular. Thus, up to harmless diagonal sign conventions, the orthogonal factor in the QR factorization of is the orthogonal factor of
is upper triangular. Thus, up to harmless diagonal sign conventions, the orthogonal factor in the QR factorization of is the orthogonal factor of  . So the whole question reduces to understanding
. So the whole question reduces to understanding  . Write
. Write  Since is lower triangular, its only possible nonzero entries below the diagonal occur when
Since is lower triangular, its only possible nonzero entries below the diagonal occur when  .
.
For such entries, 
This formula is the heart of the proof. Because the eigenvalues have been ordered by decreasing magnitude, whenever we have  Therefore
Therefore  It follows that every strictly lower-triangular entry of tends to zero. Since has ones on the diagonal, the diagonal of is still equal to one. Hence
It follows that every strictly lower-triangular entry of tends to zero. Since has ones on the diagonal, the diagonal of is still equal to one. Hence 
More quantitatively,  The slowest decay comes from the largest ratio
The slowest decay comes from the largest ratio  with . Under the ordering
with . Under the ordering  this worst adjacent ratio is
this worst adjacent ratio is  Thus there is a constant
Thus there is a constant  such that
such that 
Now return to Since  , the matrix tends to . Taking QR factorizations is a smooth operation near a nonsingular matrix whose leading principal minors do not vanish. Therefore the orthogonal factor of tends to the orthogonal factor of , namely itself, up to possible sign changes of columns. Consequently,
, the matrix tends to . Taking QR factorizations is a smooth operation near a nonsingular matrix whose leading principal minors do not vanish. Therefore the orthogonal factor of tends to the orthogonal factor of , namely itself, up to possible sign changes of columns. Consequently,  where
where  is a diagonal matrix with diagonal entries
is a diagonal matrix with diagonal entries  . These signs are harmless: changing the sign of an eigenvector does not change the diagonalization.
. These signs are harmless: changing the sign of an eigenvector does not change the diagonalization.
Finally, recall that Since approaches up to signs, we obtain  This proves convergence.The proof also reveals the rate. The error is carried by the lower-triangular part of , and each entry of that lower-triangular part is multiplied by a factor
This proves convergence.The proof also reveals the rate. The error is carried by the lower-triangular part of , and each entry of that lower-triangular part is multiplied by a factor  Thus the convergence is controlled by ratios of eigenvalue magnitudes. The worst ratio is
Thus the convergence is controlled by ratios of eigenvalue magnitudes. The worst ratio is  and therefore the basic global convergence rate is
and therefore the basic global convergence rate is 
This is the essential mechanism: powers of magnify the dominant eigendirections faster than the weaker ones; QR factorization extracts the resulting orthonormal frame; and the amount of remaining contamination decays like eigenvalue ratios.
The practical symmetric QR algorithm
The QR algorithm described above is the conceptual algorithm. The practical algorithm for a dense real symmetric matrix uses four refinements: tridiagonalization, implicit QR steps, shifts, deflation.
Each refinement keeps the same basic principle: replace the matrix by an orthogonally similar matrix, so the eigenvalues are unchanged.
- Tridiagonalization
Given a dense real symmetric matrix , first reduce it to tridiagonal form:  where
where 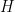 is orthogonal. Thus
is orthogonal. Thus  has the same eigenvalues as . The matrix has the form
has the same eigenvalues as . The matrix has the form

The reduction is done by Householder reflectors  At step
At step  , the reflector
, the reflector  is chosen so that
is chosen so that  zeros out the entries below the first subdiagonal in column . Because the reflector is applied on both sides, symmetry is preserved. After
zeros out the entries below the first subdiagonal in column . Because the reflector is applied on both sides, symmetry is preserved. After  such steps, the matrix is tridiagonal.
such steps, the matrix is tridiagonal.
This is the decisive practical reduction. A dense symmetric matrix has  entries, while a tridiagonal matrix has only
entries, while a tridiagonal matrix has only  relevant entries. The eigenvalue problem is unchanged, but the later QR steps become much cheaper.
relevant entries. The eigenvalue problem is unchanged, but the later QR steps become much cheaper.
2. Shifts
On an active tridiagonal block, choose a shift  and compute
and compute  Then set
Then set  Equivalently,
Equivalently,  So a shifted QR step is still an orthogonal similarity transformation. The eigenvalues are not changed. The role of the shift is to improve the convergence rate. If is close to an eigenvalue near the bottom of the active block, then the corresponding bottom subdiagonal entry tends to shrink much faster. The shift will change the convergenve as follows.
So a shifted QR step is still an orthogonal similarity transformation. The eigenvalues are not changed. The role of the shift is to improve the convergence rate. If is close to an eigenvalue near the bottom of the active block, then the corresponding bottom subdiagonal entry tends to shrink much faster. The shift will change the convergenve as follows.
 Thus, if is close to
Thus, if is close to  but not close to
but not close to  , the ratio is small and the bottom subdiagonal decays rapidly.
, the ratio is small and the bottom subdiagonal decays rapidly.
A simple choice is the Rayleigh shift,  This is because we are assuming for large enough k, this entry is already to close to an eigenvalue so that above argument shows the shift improve the covnergence.
This is because we are assuming for large enough k, this entry is already to close to an eigenvalue so that above argument shows the shift improve the covnergence.
A better practical choice is the Wilkinson shift. It uses the eigenvalue of the trailing  block
block  that is closer to
that is closer to 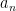 .
.
3. The implicit QR step
One could form  and explicitly, but that would destroy the efficiency gained from tridiagonalization. Instead, the practical algorithm uses an implicit QR step. Start with the shifted tridiagonal matrix
and explicitly, but that would destroy the efficiency gained from tridiagonalization. Instead, the practical algorithm uses an implicit QR step. Start with the shifted tridiagonal matrix  . Its first column has only two possibly nonzero entries:
. Its first column has only two possibly nonzero entries: 
Choose a Givens rotation  acting on coordinates
acting on coordinates  that zeros the second entry. Apply it as a similarity transformation:
that zeros the second entry. Apply it as a similarity transformation:  This creates one extra nonzero entry just outside the tridiagonal band. This extra entry is called a bulge. Next choose a Givens rotation
This creates one extra nonzero entry just outside the tridiagonal band. This extra entry is called a bulge. Next choose a Givens rotation 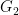 acting on coordinates
acting on coordinates  to remove the bulge. This creates a new bulge one step lower. Continue in this way:
to remove the bulge. This creates a new bulge one step lower. Continue in this way:  The bulge is chased down the matrix until it disappears at the bottom. The final matrix is again symmetric tridiagonal. Thus the implicit step performs the same shifted QR similarity transformation,
The bulge is chased down the matrix until it disappears at the bottom. The final matrix is again symmetric tridiagonal. Thus the implicit step performs the same shifted QR similarity transformation,  but without forming the full matrix . It uses only local rotations on neighboring coordinates. This is why one QR step on a tridiagonal matrix costs only
but without forming the full matrix . It uses only local rotations on neighboring coordinates. This is why one QR step on a tridiagonal matrix costs only  operations.
operations.
4. Deflation
As the QR iteration proceeds, some subdiagonal entries become very small. If  is numerically negligible. We set
is numerically negligible. We set  The tridiagonal matrix then splits into two smaller independent blocks:
The tridiagonal matrix then splits into two smaller independent blocks:  The eigenvalue problem has now separated into two smaller eigenvalue problems. This is deflation.
The eigenvalue problem has now separated into two smaller eigenvalue problems. This is deflation.
In summary, the practical symmetric QR algorithm proceeds as follows. Starting with a dense real symmetric matrix , one first makes a single orthogonal reduction to tridiagonal form,  Then, on each active tridiagonal block, one chooses a shift and performs an implicit shifted QR step, implemented by Givens rotations and bulge chasing, so that Whenever a subdiagonal entry becomes negligible, it is set to zero and the matrix deflates into smaller independent blocks. The process continues until every active block is
Then, on each active tridiagonal block, one chooses a shift and performs an implicit shifted QR step, implemented by Givens rotations and bulge chasing, so that Whenever a subdiagonal entry becomes negligible, it is set to zero and the matrix deflates into smaller independent blocks. The process continues until every active block is  . The remaining diagonal entries are the computed eigenvalues. Thus tridiagonalization makes the problem sparse, implicit QR preserves that sparsity, shifts accelerate convergence, and deflation makes the problem shrink.
. The remaining diagonal entries are the computed eigenvalues. Thus tridiagonalization makes the problem sparse, implicit QR preserves that sparsity, shifts accelerate convergence, and deflation makes the problem shrink.
