From a set  , assume that we want to pick elements that are not divisible by any primes in a set
, assume that we want to pick elements that are not divisible by any primes in a set  . Let
. Let  be the set of element of divisible by
be the set of element of divisible by 
If we write the inclusion-exclusion to sift out the element divisible by some prime in , we get

Even if we know very accurately, the above expression is not useful if has a lot of primes because the sum has too many terms, the error terms with add up.
So we need approximations to 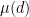 that are supported on
that are supported on  small so that we have lesser number of terms in the sifting sum.
small so that we have lesser number of terms in the sifting sum.
Say we want an upper bound, one way to achieve is to make sure that you always count elements not divisible by and add flexibility to include more elements.
So we want  such
such


Selberg choice is the the following square form to ensure positivity.

with  .
.
Assume 
where  is multiplicative function telling us the probability of a random element being divisible by ,
is multiplicative function telling us the probability of a random element being divisible by , 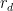 is the error and
is the error and  is the total size of .
is the total size of .

![\displaystyle = \sum_{d_1, d_2 |P} \lambda_{d_1}\lambda_{d_2} \sum_{n\in A , d_1, d_2|n} =\sum_{d_1, d_2|P} \lambda_{d_1}\lambda_{d_2} |A_{[d_1, d_2]}|](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Csum_%7Bd_1%2C+d_2+%7CP%7D+%5Clambda_%7Bd_1%7D%5Clambda_%7Bd_2%7D+%5Csum_%7Bn%5Cin+A+%2C+d_1%2C+d_2%7Cn%7D+%3D%5Csum_%7Bd_1%2C+d_2%7CP%7D+%5Clambda_%7Bd_1%7D%5Clambda_%7Bd_2%7D+%7CA_%7B%5Bd_1%2C+d_2%5D%7D%7C&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = \sum_{d_1, d_2|P} \lambda_{d_1}\lambda_{d_2} g([d_1, d_2])X + )\left( \sum_{d_1, d_2|P} \lambda_{d_1}\lambda_{d_2} r_{[d_1, d_2]} \right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Csum_%7Bd_1%2C+d_2%7CP%7D+%5Clambda_%7Bd_1%7D%5Clambda_%7Bd_2%7D+g%28%5Bd_1%2C+d_2%5D%29X+%2B+%29%5Cleft%28+%5Csum_%7Bd_1%2C+d_2%7CP%7D+%5Clambda_%7Bd_1%7D%5Clambda_%7Bd_2%7D+r_%7B%5Bd_1%2C+d_2%5D%7D+%5Cright%29&bg=ffffff&fg=000000&s=0&c=20201002)
We now ignore the error terms and try to find  that minimize the main term. This is a quadratic form
that minimize the main term. This is a quadratic form  with coefficients
with coefficients ![{g[\lambda_{d_1}, \lambda_{d_2}].}](https://s0.wp.com/latex.php?latex=%7Bg%5B%5Clambda_%7Bd_1%7D%2C+%5Clambda_%7Bd_2%7D%5D.%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle G:= \sum_{d_1, d_2|P} \lambda_{d_1}\lambda_{d_2} g([d_1, d_2])= \sum_{{a b c \mid P}} \sum g(a b c) \lambda_{a c} \lambda_{b c}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+G%3A%3D+%5Csum_%7Bd_1%2C+d_2%7CP%7D+%5Clambda_%7Bd_1%7D%5Clambda_%7Bd_2%7D+g%28%5Bd_1%2C+d_2%5D%29%3D+%5Csum_%7B%7Ba+b+c+%5Cmid+P%7D%7D+%5Csum+g%28a+b+c%29+%5Clambda_%7Ba+c%7D+%5Clambda_%7Bb+c%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where we denoted  , with the gcd
, with the gcd 




Let us call define  by
by

We have

So we have


With

the form is diagaonalized to

Now we rewrite in terms of 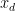 .
.

The constraint gives

Assume the support of is 
Cauchy -Schwarz implies

Therefore

where

The optimal vector satisifies

And we get the main term  . So we have
. So we have

where
![\displaystyle R \le \sum_{\substack{d_{1}, d_{2} \leqslant \sqrt{D} \\ d_{1}, d_{2} \mid P(z)}} |\lambda_{d_1}| |\lambda_{d_2}|\left|r_{\left[d_{1}, d_{2}\right]}\right|](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R+%5Cle+%5Csum_%7B%5Csubstack%7Bd_%7B1%7D%2C+d_%7B2%7D+%5Cleqslant+%5Csqrt%7BD%7D+%5C%5C+d_%7B1%7D%2C+d_%7B2%7D+%5Cmid+P%28z%29%7D%7D+%7C%5Clambda_%7Bd_1%7D%7C+%7C%5Clambda_%7Bd_2%7D%7C%5Cleft%7Cr_%7B%5Cleft%5Bd_%7B1%7D%2C+d_%7B2%7D%5Cright%5D%7D%5Cright%7C+&bg=ffffff&fg=000000&s=0&c=20201002)
We can see that

Thus

Note the  is the main term for the sifted set if the events
is the main term for the sifted set if the events  are independent.
are independent.
To get the good upper bounds we need to show that  is large.
is large.
To get bounds on  , we need bounds on . I f we prove
, we need bounds on . I f we prove  , we get
, we get

So we need to look at the how the optimal look like.



Hence we have 
The shape of the sieve weight .
We want to evaluate . Without the the restriction  we get
we get

if we have something like  in some average sense where
in some average sense where



Thus behaves like a smooth truncation of . Instead of the optimal vectors, we could start with vectors of the shape

where is  is a smooth function on
is a smooth function on ![{[-\infty, 1]}](https://s0.wp.com/latex.php?latex=%7B%5B-%5Cinfty%2C+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and similar results.
and similar results.
The smoothness is important because the sharp truncation  gives a lot of weight to numbers that are not free of small prime factors. In fact, we have
gives a lot of weight to numbers that are not free of small prime factors. In fact, we have

whereas the smooth weights above give

and hence the main contribution comes from numbers with few number of small prime factors.
But we also have

so the contribution of numbers with small prime factors is not too small, because by the above estimate, if we weight it by 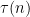 , that the contribution amplifies and dominates the sum.
, that the contribution amplifies and dominates the sum.
The sign of the resulting sieve weight:
![\displaystyle \alpha_d =\sum_{[d_1, d_2]=d} \lambda_{d_1}\lambda_{d_2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Calpha_d+%3D%5Csum_%7B%5Bd_1%2C+d_2%5D%3Dd%7D+%5Clambda_%7Bd_1%7D%5Clambda_%7Bd_2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Looking at the formula for  we saw that has the same sign as , but this doesn’t mean will also have the same sign.
we saw that has the same sign as , but this doesn’t mean will also have the same sign.
But

We can also prove that 
GPY Weights:
Instead of choosing to be constant, if we choose

the resulting sieve weights looks like

that is the like the weights for dimension 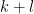 . These are helpful to get small gaps between primes.
. These are helpful to get small gaps between primes.
Dependence on :
If the primes sifted is  , then for a fixed
, then for a fixed  (the dimension, average classes mod
(the dimension, average classes mod  that need to be sifted from ), as
that need to be sifted from ), as  becomes small relative to
becomes small relative to  (the support of the sieve weight), the main term converges to the
(the support of the sieve weight), the main term converges to the 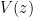 . But the rate of convergence is small compared to other combinatorial sieves like beta sieve.
. But the rate of convergence is small compared to other combinatorial sieves like beta sieve.
The Selberg sieve can be used to create lower bound sieve which for large , gives better lower bound in a wider range of ,  compared to other combinatorial sieves.
compared to other combinatorial sieves.
Also for large , the main terms wont change much if we increase from  to a bigger values. That is primes large than have no effect on Selberg’s upper bound.
to a bigger values. That is primes large than have no effect on Selberg’s upper bound.
Application to Brun-Titichmarch inequality:
If we take a short interval ![{[x, x+y]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2C+x%2By%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and we want to count primes in the arithmetic progression
and we want to count primes in the arithmetic progression  , we have
, we have

with  , we have
, we have

So taking  , we get
, we get

It’s possible to remove the error by other methods.
