I have been interested in sorting algorithms and structures since a long time. The simple looking theory has lot of rich and beautiful structure.
Let us see what are the most natural ideas for sort. First of all given a sequence of elements, we use some properties of these elements to order these elements. The elements themselves need not be objects like numbers with any extra structure like addition and multiplication. Any finite number of elements can be ordered. Also large structure can also have the linear order. For instance the linear of R. Some times we can even give some ordering on the objects based on the work we have. For instance points in 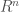
Here I discuss the theory for sequences of numbers and sequences of finite alphabets. The first things is the structure of R, and the second thing is some linear structure in a finite set. Here again if we restrict to sequences in Z, due the rigid structure of Z the theory is different. Although, the general framework fits here, we can do much butter by exploiting this rigidity.
Now suppose we have a sequence on n elements. We have to sort it based on the property I decide for prioritisation. The property assigns n number values to these elements, whose order structure is isomorphic to the order on these elements. Now we just treat the sequence of the objects as the sequence of these key values.
The sort sequences has some obvious properties like
1.the first element in the sorted sequence has the least key value.
2. For any subsequence of the original sequence , its image in the sorted sequence is also sorted.
3. If an element k is fixed that is it is in its correct position, we just need to sort the remaining set of elements.
We can make use of these properties to devise various algorithms. Most obvious for instance is to find the minimum element for the sequence, then the minimum of rest of the elements and so on. Now to discuss the complexity of this algorithm we need to assume a model for the entire computations. For instance if we our sequence to be represented by an array of element a(1),a(2),…,a(n), then to find the minimum element in the sequence we need to start with the first element take it to be the min and go over the array and update the min whenever you encounter another object with lesser key value. This take n computation to find the minimum for n elements. Once we find the minimum we know that it is the first element in the sorted sequence, so we can create a new array and add this as the first element or else we can swap the min with first element of the original sequence itself and then continue to sort the sequence form a(2). Another entirely different way is this. Suppose the entire sequence of objects is given as a heap. Heap is a way representing the data in a binary tree such that every node has its value less than its children. It can be seen that finding the minimum takes O(1) computation. Just the root node has the minimum value. But once we remove it the heap structure of remaining sequence is lost. For structural information about heaps look at ……..The operation likes deletion, insertion into the heap take place in O(logn) steps. Note that in the case of arrays this takes just constant time.
So summing the above, to discuss algorithms we need to first agree upon several things like data structure -how data is represented, what kind of processes/operations are basic, cost of each operation etc. We assume that accessing the root node in heap or the first element of array take constant time etc, so that the once we fixed upon that structure and the ways in which we can get the required information about the structure, the same function may take different times to be calculated as the case in minimum above. Also, the problem will be completely different based on the model of computation, that is based on the how we assume the processes to take place. Automata, boolean circuits are, sorting circuits some such models.
In the above we saw we saw how the data structures and the models of computation affect the complexity of the problem. Going further with the most natural way to sort, we may use a kind of inductive approach. We sort the first n-1 elements and then use this information to find the complete sort sequence. In the array structure once we know the sorted sequence of first elements we may insert the nth elements into its correct place by finding where it fits in this sorted sequence. The natural way is to search for itself position by going over the array from the start or the end. We may improvise this by actually using structure of sorted sequence in a better way. That is to find it position in the sequence we use the binary search instead of the linear search. Thus it takes T(n)=T(n-1)+O(logn) computations so that we have a T(n)=O(nlogn). But here assumed that we can insert the element into itself with constant steps. But here again the data structural aspects come up and for a structure like array it may not be possible to insert the element in O(1) in the middle. We may have to use some other structure like linked lists.
In the above we have used the second observation and a better way to insert an element so that we can sort inductively. Similarly we may use a divide and conquer approach in which we may assume two parts of the sequence are sorted and then use these sorted sequences to compute the total sorted sequence. So the important thing is how one merges these sorted sequences. We can do an O(n) merging thereby leading to a T(n)=2T(n/2)+O(n) =O(nlogn) sorting.
Now we shall see how we can use the third observation. Because we are reduced the smaller problems of sorting left and right parts of an element in the sequence once we know that it is in its right position , we just pick a random element and then make sure it is fixed by swapping the elements.Also we make sure all the elements greater than this element are on on the right side and less than it in the left side. So we are now left to the small problems of sorting the left and right sides. (This may appear to be like the above merge sort, but it is completely different, there is no merging involved!) The efficiency of the algorithm depends on the choosing a good pivot so that the no of swappings are small. An arbitrary pivot may lead to large number of swappings in the worst case. But on the average a purely random selection of pivot gives us a O(nlogn) average case algorithm with worst case bound O(n^2). The worst case may occur for say selecting end elements in the case of already sorted or near sorted sequence. This was about the random selection of the pivot. We may deterministically select pivots and improve the algorithm.The theory of selecting the pivot (selection algorithms) is a very nice and interesting web of ideas. I will discuss it in a post later.(This post has become a lot bigger than I thought!)
I will end this post by saying that O(nlogn) is the best one can do for sorting using just the comparisons. We just use comparisons and the information obtained from them to build the sorted sequence. Sorting is one of the very few problems I know for which there exist algorithms that can be proved to be optimal. Now coming to the proof of optimality, the argument is information theoretic. We have O(n!) possibilities ( n! if the elements are assumed to be distinct) for the number of possible sequences. To decide what the sequence was we need atleast log n! bits of information. But since each comparison gives atmost two bits of information (either a>b or a<=b), we have k,the number of comparisons required to be greater than log n!. So we get k>nlogn-n.This shows we require atleast nlogn comparisons to find out the sequence. This argument is represented as a decision tree in computer science. The leaf nodes corresponds the number of possibilities and the nodes corresponds to decision at each comparision.
